
DevOps has become one of the most talked-about concepts in modern software delivery. It’s often associated with automation tools, CI/CD pipelines, and cloud-native architectures. But the truth is, DevOps isn’t primarily about technology. It’s about culture. Without cultural transformation, even the most advanced tools will fail to deliver the promised benefits.
So, what exactly is DevOps culture? Why did it emerge? Why should organizations care? And perhaps most importantly, how do we build it? This article dives deep into these questions, drawing on real-world examples and lessons learned from enterprise transformations, including insights from projects.
What Is DevOps Culture?
DevOps culture is more than a set of practices. It’s a mindset that transforms how organizations build and deliver software. At its core, DevOps culture breaks down silos between development, operations, and security teams, fostering collaboration and shared responsibility across the entire software delivery lifecycle. Instead of developers writing code and tossing it over the wall to operations, DevOps encourages everyone involved, including developers, testers, security engineers, and operations, to work toward a common goal: delivering reliable, secure software quickly and efficiently.
To understand DevOps culture, it helps to look at the Three Ways described in The Phoenix Project, which serve as guiding principles for high-performing technology organizations:
The First Way: Flow
Flow is about creating a fast, smooth movement of work from development to operations and ultimately to the customer. It emphasizes systems thinking, or viewing the entire value stream as one continuous system rather than isolated silos. Practices like reducing batch sizes, limiting work in progress, and eliminating bottlenecks help accelerate delivery while improving quality. In a DevOps culture, flow ensures that ideas move quickly from concept to production without unnecessary friction.
The Second Way: Feedback
Feedback is the lifeblood of continuous improvement. The Second Way focuses on shortening and amplifying feedback loops so problems are detected and corrected early. Automated testing, continuous integration, proactive monitoring, and regular retrospectives create a two-way exchange of insights between development and operations. This principle reinforces shared responsibility and helps teams learn from each other, preventing defects from cascading downstream.
The Third Way: Continuous Learning and Experimentation
The Third Way promotes a culture of continual learning and innovation. It encourages teams to take calculated risks, experiment, and learn from failures without fear of blame. Practices like blameless post-mortems, dedicated time for experimentation, and open knowledge sharing make improvement part of everyday work. This principle ensures that organizations adapt quickly to change and continuously evolve their capabilities.
Together, these Three Ways form the backbone of DevOps culture. They shift the focus from isolated tasks to holistic outcomes, from rigid processes to adaptive learning, and from siloed accountability to shared ownership. When these principles are embraced, DevOps becomes more than a methodology. It becomes a cultural movement that drives speed, quality, and resilience.
Why Does DevOps Culture Exist?
The roots of DevOps culture lie in the shortcomings of traditional software development models. Waterfall methodologies, with their rigid phases and long release cycles, were ill-suited for a world where customer expectations change overnight. Agile development addressed part of the problem by speeding up coding and testing, but it often left operations behind. The result? Faster development paired with slow, painful deployments.
The 2009 "10+ Deploys Per Day" talk by John Allspaw and Paul Hammond at the Velocity conference is widely considered the spark that ignited the DevOps movement. At the time, Flickr was deploying code to production more than 10 times per day, which was revolutionary when most companies were doing quarterly or monthly releases. The talk challenged the conventional wisdom that development and operations had inherently conflicting goals. Instead of accepting the "wall of confusion" between Dev (who wanted to move fast and ship features) and Ops (who wanted stability and minimal change), Allspaw and Hammond demonstrated how their teams collaborated through shared tools, shared metrics, and shared responsibility. They showed that with the right culture and automation, velocity and stability weren't trade-offs, but rather they reinforced each other.
The key insight was that deploying frequently actually reduces risk because each change is smaller, easier to test, and faster to roll back if needed. Their approach included automated testing, one-step builds and deploys, feature flags for safer releases, shared metrics visible to everyone, and most importantly, a culture of mutual respect and trust between developers and operations. The talk resonated so deeply because it offered a practical alternative to the status quo, proving that cross-functional collaboration, automation, and continuous delivery weren't just theoretical ideals. They were achievable realities. This presentation became the blueprint for what would soon be formalized as the DevOps movement, influencing countless organizations to rethink how they deliver software.
DevOps emerged as the bridge between Agile and operational excellence. It extended the principles of iteration and feedback beyond coding to include deployment, monitoring, and incident response. Organizations realized that speed without stability was a recipe for disaster. DevOps culture exists to align innovation with reliability, enabling teams to deliver value continuously without sacrificing quality.
Why Should We Care About DevOps Culture?
Culture drives behavior, and behavior drives outcomes. You can implement every automation tool on the market, but if your teams don’t collaborate, share responsibility, and embrace continuous improvement, you’ll never achieve true DevOps maturity.
DevOps culture matters because it impacts every metric that matters to the business:
- Time-to-market: Faster releases mean quicker response to customer needs.
- Quality: Shared responsibility reduces defects and improves reliability.
- Employee engagement: Teams that collaborate and learn together are more motivated.
- Business value: Efficient delivery translates to competitive advantage and profitability.
How Do We Get There?
Building a DevOps culture isn't about buying a tool or adopting a framework. It's about changing mindsets and behaviors through deliberate practices, organizational design, and measured progress. Here's a comprehensive roadmap for cultural transformation:
Specific Practices That Enable DevOps Culture
Infrastructure as Code (IaC)
Infrastructure as Code treats infrastructure provisioning like software development, with version control, code reviews, and automated testing. Instead of manually configuring servers through GUI consoles or ad-hoc scripts, teams define infrastructure declaratively in files that can be reviewed, tested, and deployed consistently.
For example, using Terraform, you might define an Azure Kubernetes Service cluster like this:
resource "azurerm_kubernetes_cluster" "main" {
name = "prod-aks-cluster"
location = azurerm_resource_group.main.location
resource_group_name = azurerm_resource_group.main.name
dns_prefix = "prodaks"
default_node_pool {
name = "default"
node_count = 3
vm_size = "Standard_D2_v2"
}
identity {
type = "SystemAssigned"
}
}
This approach makes infrastructure changes transparent, auditable, and repeatable. When operations engineers and developers collaborate on IaC, they build shared understanding of both application and infrastructure requirements. Code reviews become opportunities for knowledge transfer. Automated testing catches configuration drift before it reaches production.
Shift-Left Security Practices
Shift-left security means integrating security checks early in the development pipeline rather than treating security as a gate before production. This includes static application security testing (SAST) in CI pipelines, dependency scanning for vulnerable packages, container image scanning, and infrastructure security validation.
For instance, integrating GitHub Advanced Security into your CI/CD pipeline automatically scans for secrets, detects vulnerable dependencies, and runs CodeQL queries on every pull request. Developers get immediate feedback about security issues when the fix is cheapest and easiest. Security teams define policies as code, like "no critical vulnerabilities in production" or "all secrets must be stored in Azure Key Vault," and automation enforces them consistently.
The cultural shift here is critical: security isn't something done to developers; it's something done with them. Security engineers become enablers rather than gatekeepers, providing tools, training, and guardrails that help developers ship secure code confidently.
Observability and Monitoring Strategies
Observability goes beyond traditional monitoring. While monitoring tells you what is wrong (CPU usage is high, error rate increased), observability helps you understand why by providing insights into system behavior through logs, metrics, traces, and events.
A mature observability strategy includes:
- Structured logging with correlation IDs to trace requests across distributed systems
- Distributed tracing to visualize request flows and identify bottlenecks (using tools like Jaeger or Azure Application Insights)
- Metrics dashboards that show business KPIs alongside technical metrics
- Proactive alerting based on SLOs (Service Level Objectives) rather than arbitrary thresholds
- Blameless postmortems that treat incidents as learning opportunities
When developers have access to production metrics and logs, they understand how their code performs in the real world. When operations teams understand application architecture and business context, they can prioritize incidents effectively. Shared observability creates shared responsibility.
ChatOps and Communication Patterns
ChatOps brings operational work into chat platforms like Slack or Microsoft Teams, making actions transparent and collaborative. Instead of operations engineers deploying code through opaque terminal sessions, deployments happen via chat commands visible to the entire team.
For example, a deployment might look like: /deploy api-service v2.3.1 to production executed in a Slack channel. The bot responds with deployment status, runs automated tests, and notifies the team when complete. If issues arise, the entire team sees the context and can collaborate on resolution in the same thread.
This transparency breaks down information silos. Junior engineers learn by observing how seniors troubleshoot issues. Product managers understand operational challenges. Security teams can audit actions without requesting logs. ChatOps doesn't just automate tasks; it democratizes knowledge.
Team Topologies: Organizing for Flow
DevOps culture requires deliberate organizational design. The book Team Topologies by Matthew Skelton and Manuel Pais provides a framework for structuring teams to optimize flow and minimize cognitive load.
Stream-Aligned Teams
These are cross-functional product teams aligned to a single value stream (a product, service, or user journey). A stream-aligned team includes developers, testers, operations expertise, and sometimes designers or data analysts. They own their service end-to-end, from code to production. For example, a "Checkout Service Team" owns everything related to the checkout experience: backend APIs, frontend components, database schemas, infrastructure, and monitoring.
This structure eliminates handoffs and waiting. The team can move quickly because they don't depend on separate operations or QA teams to progress. They feel ownership because they're accountable for outcomes, not just outputs.
Platform Teams
Platform teams build internal products that reduce cognitive load for stream-aligned teams. They provide self-service capabilities like CI/CD pipelines, infrastructure templates, observability tooling, and developer portals. A good platform team treats other engineering teams as customers, focusing on developer experience and ease of use.
For instance, a platform team might create a "golden path" deployment pipeline where stream-aligned teams can deploy containerized applications to Kubernetes with a single YAML file, while the platform handles secrets management, network policies, monitoring setup, and compliance checks automatically.
Enabling Teams
Enabling teams help stream-aligned teams adopt new technologies and practices. They're specialists (security engineers, SREs, data engineers) who embed temporarily with product teams to transfer knowledge. Unlike traditional centralized teams that do work for others, enabling teams work with others to build capability.
For example, an enabling team might help a product team adopt observability practices by pairing on instrumentation code, explaining tracing concepts, and setting up dashboards. After a few weeks, the product team has the skills to continue independently.
Complicated Subsystem Teams
These teams handle complex technical domains that require specialized expertise, like machine learning models, payment processing, or compliance engines. They provide services to stream-aligned teams through well-defined APIs.
The key principle is team interaction modes: collaboration (working together), X-as-a-Service (consuming through APIs), and facilitation (helping others learn). Clear interaction modes prevent teams from stepping on each other's toes and reduce cognitive overload.
Transformation Roadmap: From Assessment to Optimization
DevOps transformation isn't a big-bang change. It's a phased journey that respects organizational constraints while driving continuous improvement.
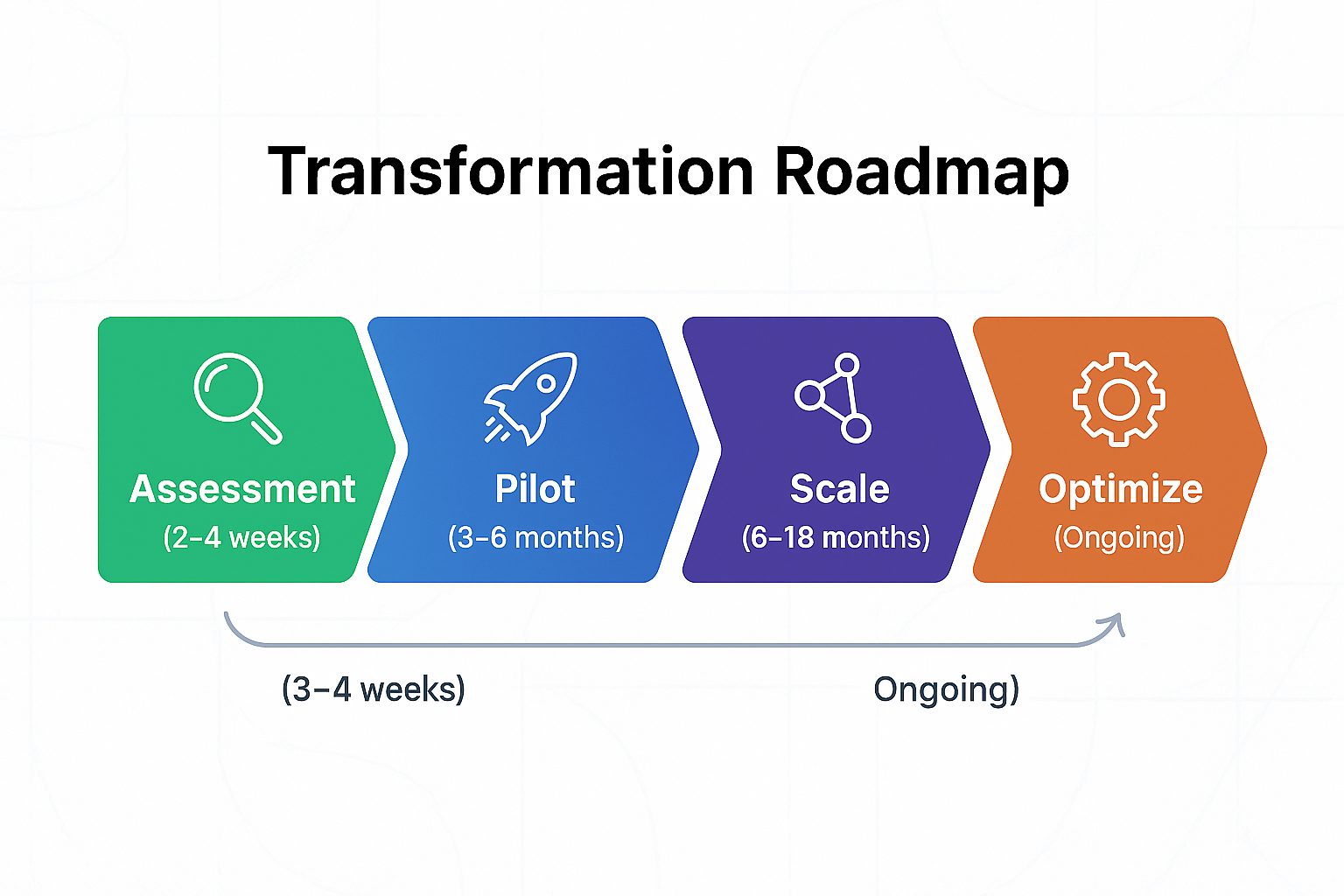
Phase 1: Assessment (2-4 weeks)
Start by understanding your current state. Conduct interviews with developers, operations, security, and business stakeholders. Map your value streams: how does code move from idea to production? Identify bottlenecks, waste, and cultural friction points.
Measure baseline metrics: How often do you deploy? What's your lead time from commit to production? What percentage of deployments cause incidents? How long does it take to recover from failures? These become your benchmarks for improvement.
Assess organizational readiness. Who are your potential champions? What's leadership's appetite for change? What constraints (regulatory, technical, political) will you face? Create a stakeholder map and change management strategy.
Phase 2: Pilot (3-6 months)
Select one stream-aligned team (ideally working on a non-critical but meaningful product) to pilot DevOps practices. This team becomes your laboratory for experimentation and your showcase for success.
Provide this team with support: automation tools, training, time to refactor, and executive air cover to take calculated risks. Help them implement continuous integration, automated testing, and deployment automation. Introduce infrastructure as code. Set up observability. Establish metrics dashboards.
Document everything: what worked, what didn't, and what you learned. Run retrospectives. Share progress through demos and internal blog posts. The goal is to build a proven model and create advocates who can help spread practices to other teams.
Phase 3: Scale (6-18 months)
With a successful pilot, begin scaling practices across the organization. This isn't about mandating tools; it's about sharing patterns, providing platforms, and building momentum.
Form a platform team to codify lessons learned from the pilot into reusable services. Create documentation, runbooks, and training materials. Establish communities of practice where practitioners share knowledge. Identify and empower champions in each department.
Roll out changes incrementally. Start with teams that are ready and willing. Let success stories drive adoption. Provide enabling team support to teams that need extra help. Measure progress against DORA metrics and celebrate improvements publicly.
Phase 4: Optimize (Ongoing)
DevOps transformation never "finishes." Optimization is continuous. Regularly revisit metrics and identify new bottlenecks. Experiment with advanced practices like chaos engineering, feature flags, and progressive delivery.
Invest in organizational learning. Run internal conferences. Encourage teams to attend external conferences and bring back ideas. Create time and space for innovation. Most importantly, maintain the cultural practices that got you here: blameless postmortems, cross-functional collaboration, and psychological safety.
Change Management Tactics: Building Momentum
Cultural change is hard because it threatens the status quo. People fear losing status, competence, or control. Here's how to overcome resistance:
Start with Why
Connect DevOps transformation to business outcomes people care about. For executives, emphasize competitive advantage and faster time-to-market. For engineers, highlight reduced toil and more interesting work. For operations, emphasize stability through automation and reduced burnout. Make the case compelling and personal.
Build Champions
Identify influential people at every level who believe in the vision. These aren't necessarily managers. They're people others trust and respect. Empower them with resources, training, and visibility. Let them tell the story authentically.
Create Quick Wins
People need to see progress quickly. Choose visible pain points with achievable solutions. Automate a painful manual process. Reduce deployment time from hours to minutes. Fix a longstanding monitoring gap. Document the improvement and share it widely. Small wins build confidence that larger changes are possible.
Provide Psychological Safety
Fear kills transformation. If people are punished for failures or blamed for outages, they'll stick to safe, slow processes. Leaders must model vulnerability, admit their own mistakes, and celebrate learning from failures. Make it safe to experiment, to ask questions, and to challenge assumptions.
Make the Transition Easy
Reduce friction wherever possible. Provide training before expecting new skills. Offer pairing and mentoring. Create clear documentation. Build self-service tools. Don't expect people to figure it out alone.
Metrics That Matter: DORA Metrics Explained
The DevOps Research and Assessment (DORA) team identified four key metrics that distinguish elite performers from low performers. These metrics should guide your transformation:
Deployment Frequency
How often does your organization deploy code to production? Elite teams deploy multiple times per day. Low performers deploy monthly or less. Higher deployment frequency indicates that your teams can deliver value quickly and respond rapidly to feedback.
To improve deployment frequency, reduce batch sizes (smaller pull requests, feature flags), automate testing and deployment, and eliminate manual approval gates that don't add value.
Lead Time for Changes
How long does it take for a commit to reach production? Elite teams measure lead time in hours. Low performers measure it in months. Short lead times mean faster feedback cycles and reduced risk per deployment.
To improve lead time, identify and eliminate bottlenecks in your delivery pipeline. Common culprits include slow test suites, manual handoffs, and infrequent merge cycles. Visualize your value stream and optimize the slowest steps.
Mean Time to Recovery (MTTR)
When incidents occur, how quickly can you restore service? Elite teams recover in under an hour. Low performers take more than a week. Fast recovery requires excellent observability, practiced incident response, and the ability to roll back or roll forward quickly.
To improve MTTR, invest in monitoring and alerting, practice incident response through game days, automate rollback procedures, and conduct blameless postmortems that focus on system improvements rather than individual blame.
Change Failure Rate
What percentage of deployments cause production incidents? Elite teams have change failure rates under 15%. Low performers are above 45%. Lower change failure rates indicate better quality practices and effective feedback loops.
To improve change failure rate, strengthen automated testing (unit, integration, contract, and end-to-end tests), implement progressive delivery techniques (canary deployments, blue-green deployments), and use feature flags to decouple deployment from release.
These four metrics provide a balanced view of software delivery performance. Track them visibly, review them regularly, and use them to guide improvement experiments. But remember: metrics are means to an end, not the end itself. The goal is better outcomes for customers and teams, not just better numbers.
This is a lot of information to digest. Just remember,
Start with collaboration. Encourage developers and operations to work together from the beginning of a project. Create cross-functional teams that share ownership of outcomes. This was a key takeaway from the a recent project, where teams learned to align backlog management with deployment strategies, reducing friction between roles.
Invest in automation, but pair it with process improvement. Automate repetitive tasks like builds, tests, and deployments to free up time for innovation. Use metrics and monitoring to create feedback loops that inform decisions and drive continuous improvement.
Most importantly, lead by example. Culture change starts at the top. Leaders must champion collaboration, transparency, and learning. Celebrate successes, learn from failures, and make DevOps a shared responsibility across the organization.
What Are the Benefits?
The benefits of DevOps culture are well-documented and measurable. Organizations that embrace it see:
- Faster delivery cycles.
- Improved software quality.
- Greater agility in responding to market changes.
- Higher employee satisfaction.
- Increased ROI through efficiency and innovation.
- Increased Customer satisfaction
- Accelereated innovation
Companies that adopt DevOps practices report significant reductions in lead time, deployment frequency, and mean time to recovery. They also experience fewer failures and faster resolution when issues occur. These aren’t just numbers, they represent real competitive advantage.
What Are the Downsides?
DevOps culture isn’t a silver bullet. It requires investment in tools, training, and time. It can be challenging to overcome resistance to change, especially in organizations with entrenched silos. There’s also a risk of burnout if teams interpret “continuous delivery” as “never stop working.”
Another downside is the complexity of scaling DevOps across large enterprises. Aligning multiple teams, standardizing processes, and maintaining governance without stifling agility can be difficult. But these challenges are surmountable with the right strategy and leadership commitment.
We also often see several common anti-patterns emerge when introducing a DevOps culture to an organization:
- The "DevOps Team" Anti-Pattern Organizations create a separate "DevOps team" that sits between development and operations, essentially adding another silo instead of breaking them down. This team becomes a new bottleneck, handling deployments and infrastructure requests while developers and ops remain isolated. Real DevOps means cross-functional collaboration, not a new middle layer.
- Rebrand Without Reform The operations team gets renamed to "DevOps Engineers" or "Site Reliability Engineers," but nothing actually changes. They still work in isolation, receive work via tickets, and maintain the same adversarial relationship with developers. It's a cosmetic change that preserves the old culture while claiming transformation.
- Automation Without Collaboration Teams invest heavily in CI/CD pipelines, infrastructure as code, and monitoring tools, but developers and operations still don't talk to each other. Automated deployments fail because ops wasn't consulted on infrastructure requirements. Alerts fire constantly because developers don't understand operational concerns. Tools don't fix broken relationships.
- "You Build It, You Run It" Without Support Organizations push operational responsibility to developers without providing training, access, or support. Developers get paged at 3 AM for production issues they don't know how to debug. This isn't empowerment, it's abdication. Real DevOps means shared responsibility with proper enablement.
- Speed Without Safety Teams focus obsessively on deployment frequency while ignoring quality, security, and stability. They ship broken code faster, rack up technical debt, and burn out from constant firefighting. DevOps is about sustainable velocity, not just moving fast.
- Metrics Theater Organizations track deployment frequency and lead time but don't use them to drive improvement. Metrics become performative checkboxes rather than feedback mechanisms. Teams game the numbers (deploying trivial changes to boost frequency) while real problems persist.
- Tool Sprawl The organization adopts every trendy DevOps tool - Jenkins, GitLab CI, CircleCI, Kubernetes, Terraform, Ansible, Prometheus, Grafana, Datadog - without standardization or strategy. Teams spend more time integrating tools than delivering value. DevOps requires thoughtful tooling, not a collection of shiny objects.
- Security as an Afterthought "DevOps" pipelines deploy code rapidly but security reviews still happen at the end, creating a bottleneck. DevSecOps means security is integrated from the start, meaning threat modeling in design, automated security testing in CI/CD, and security champions embedded in teams.
- Agile Dev, Waterfall Ops Development teams work in two-week sprints, but operations still requires three-month lead times for infrastructure provisioning. The "agile transformation" stops at the deployment boundary. Real DevOps extends agility through the entire value stream.
- Blame Culture in Disguise Despite talk of blameless postmortems, incidents still result in finger-pointing and CYA behavior. Engineers fear making changes because failures are punished. Psychological safety is lip service, not reality. DevOps requires genuine trust and learning from failures.
These anti-patterns share a common theme: focusing on superficial changes (tools, titles, processes) while avoiding the hard work of cultural transformation: building trust, breaking down silos, fostering collaboration, and creating shared responsibility.
Common Objections and How to Address Them
When proposing DevOps cultural transformation, you'll inevitably encounter resistance. Here are the most common objections and practical ways to address them:
"We're too regulated for DevOps"
Regulation doesn't prevent DevOps. In fact, heavily regulated industries like finance and healthcare have successfully adopted DevOps practices. The key is automated compliance. Infrastructure as code, automated testing, and audit trails actually make compliance easier by creating repeatable, documented processes. Organizations like Capital One and Nationwide Insurance are proof that DevOps and regulation coexist successfully. Shift your conversation from "can we?" to "how do we automate compliance checks into our pipelines?"
"Our legacy systems can't support this"
Legacy systems are a reason to adopt DevOps, not a reason to avoid it. You don't need to rewrite everything. Start by applying DevOps principles to deployment processes, monitoring, and incident response for existing systems. Use strangler fig patterns to gradually modernize while maintaining stability. Many organizations run containerized microservices alongside mainframes. The goal isn't technology replacement; it's improving how you deliver value regardless of the underlying tech stack.
"Developers don't want operational responsibilities"
This objection often stems from misunderstanding what shared responsibility means. DevOps doesn't expect developers to become sysadmins overnight. It means providing developers with self-service platforms, observability tools, and operational expertise. Embed operations engineers into development teams to transfer knowledge. Start with on-call rotations for high-severity issues only, with proper training and escalation paths. Most developers appreciate understanding how their code runs in production. It makes them better engineers.
"We don't have time for cultural change"
This is the most dangerous objection because it confuses urgency with importance. The reality is you're already paying the cost of poor culture through slow delivery, frequent outages, and low morale. Cultural transformation doesn't require stopping work. It happens incrementally. Start with small experiments: one cross-functional team, one automated deployment pipeline, one blameless postmortem. Demonstrate value quickly and build momentum. The question isn't whether you have time for change. It's whether you can afford to keep doing things the old way.
Actionable Insights from Enterprise Projects
From internal initiatives and recent project work, several lessons stand out:
- Start small. Pilot DevOps practices in one team before scaling.
- Focus on outcomes, not tools. Tools enable culture. They don’t create it.
- Measure what matters. Track deployment frequency, lead time, and recovery time.
- Invest in people. Training and communication are as important as automation.
Final Thoughts
DevOps culture is the foundation of modern software delivery. It’s what turns automation into acceleration and collaboration into innovation. Without it, tools are just tools, and processes are just paperwork.
Building this culture takes time, effort, and leadership. But the payoff (faster delivery, better quality, happier teams, and stronger business outcomes) is worth every step.
Need help building or changing culture? I can help!